This is the first post in a series about the tactics, techniques, and behaviors that “purple teams” can use to defend their data. It builds off earlier articles about threat-informed defense and purple teaming that AttackIQ has published in recent weeks. In this series, we will describe how the AttackIQ platform can be used as a tactical purple teaming resource to enhance the capabilities and collaboration between blue and red teams to improve a company’s overall security posture.
As a starting point, let’s briefly introduce a conceptual framework for thinking about purple teaming exercises. Purple team exercises can be divided into at least five different stages that follow a workflow similar to the one below:
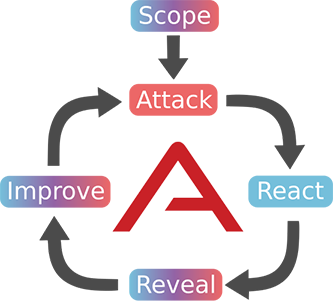
Scope
The red and blue teams sit together and define the exercise scope. This might include defining which assets will be part of it and which adversary tactics, techniques, and procedures will be executed.
Attack
The red team prepares and executes the attack according to the scope defined. In this stage, the red team can spend time researching the agreed TTPs and writing custom tooling.
React
The blue team tries to prevent and/or detect the attack that the red team executed. Ideally, the blue team should have everything in place (i.e. defensive security technologies, logging, etc.) and be able to prevent and detect the red team threat. Usually, the reality is different and that is why the two following stages are vital.
Reveal
In this stage, if the red team successfully executed the attack and the blue team was unable to fully prevent and/or detect it, the red team will reveal details of the attack so that the blue team can take action in order to improve their detection and prevention capabilities.
On the contrary, if the blue team successfully prevented and/or detected the executed threat, they will share their detection and prevention capabilities with the red team in order to allow the red team to step up their attacks against the Blue Team.
Improve
During the course of their engagement, red and blue teams work on improving their tools and offense/defense capabilities. If the red team attack was perfectly prevented and detected by the Blue Team, they should escalate their operations to challenge the blue team further. On the contrary, if the blue team was unable to detect or prevent the threat, they should leverage the details provided by the red team in the previous stage to enhance their detection and prevention capabilities.
Ideally, for each defined scope, the Attack, React, Reveal, and Improve stages should be executed cyclically to help improve the company’s security posture. This can be time and resource consuming — and it is where a Breach and Attack Simulation (BAS) platform can help.
In this series of blog posts, we will explain how to leverage the AttackIQ platform as a purple team resource to help in each of the stages we have discussed. In the first two posts of the series, we will cover the Attack stage. In the third post, we will cover the React stage. In the fourth and final post, we will describe how to automate the cycle to focus emulation plans on certain tactics, techniques and procedures and allow the red and blue teams to focus on other missions such as preparing against more advanced threats and improving their prevention and detection capabilities to improve the company’s overall security posture.
In this first post we will focus on the Attack stage. We will start from the assumption that the Scope was already executed and defined under the following two conditions: (1) all employee workstations are running GNU/Linux and (2) the adversary wants to pursue the tactic of Credential Dumping.
With these assumptions, let’s explore how our purple team operation would work.
Attack Stage: Sharpening the Red Team Toolset
Wearing a red team hat, we want to expand the credential dumping capabilities we already had for Windows (e.g. mimikatz) into GNU/Linux. Mimipenguin is a known tool that allows you to dump the login password for the current user in GNU/Linux, so it made sense to use it.
After some testing, we quickly realized that Mimipenguin has some limitations in terms of compatibility with Gnome Keyring versions, as it only works in certain versions detailed on their Readme file. Let’s imagine that in our example red team exercise the corporate environment contains a high variety of Gnome Keyring versions, so Mimipenguin is useless for this situation.
To that end, we decided to develop our own tooling in order to be able to dump user credentials regardless of the Gnome Keyring version, using a similar technique than Mimipenguin but improving the heuristics used. In addition, when we develop scenarios we try our best to make them as reliable and compatible as possible in order to avoid confusion and frustration for our users. When we use tools in the scenarios, which we do not always do, we usually modify them.
Preliminary tests
Mimipenguin leverages the vulnerability assigned with the CVE-2018-20781 in which the user’s password is kept in a session-child process spawned from the LightDM daemon, exposing the credential in cleartext.
This vulnerability is supposed to affect only versions of Gnome Keyring prior to 3.27.2, but Mimipenguin’s readme states that it is still not fixed on newer versions. Taking that into account, the first thing we planned to do was to dump the memory of the session-child process spawned from the LightDM daemon to see if the aforementioned issue was still present on Gnome Keyring 3.34.0.
The memory dump of the process was done by accessing the /proc/<PID>/maps and /proc/<PID>/mem files, using a custom Python script. From the first file, we obtained the memory addresses that define the range where the different memory regions of the process are mapped. Then we just used the grep command to find possible occurrences of our user’s password.
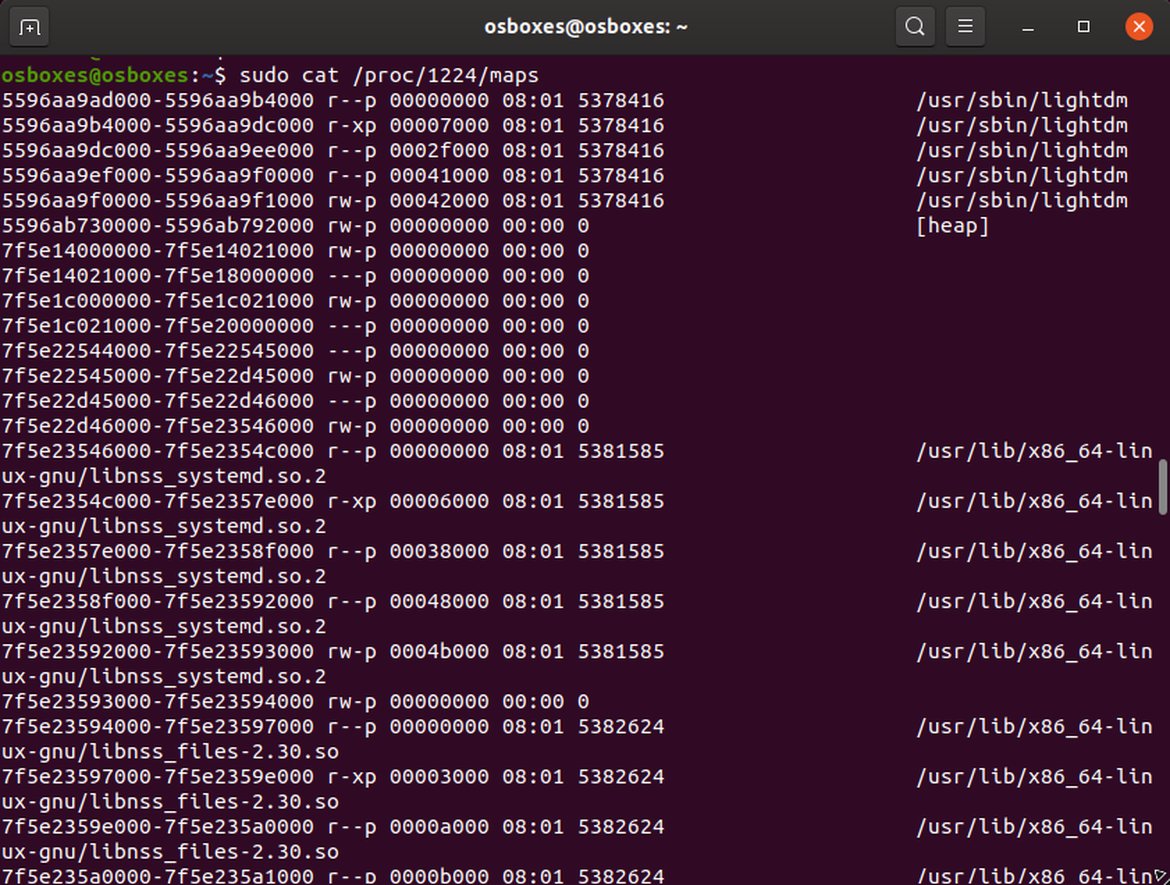
Lightdm memory maps
The results of the test were not surprising because we could not find any occurrence of the user’s password within the memory of the lightdm --session-child process. However, it was possible to retrieve the Linux Hash for the user from it. Not a great discovery but we thought that it might come in handy later on.
The natural next step was to identify other processes related to Gnome Keyring and search within their memory to see if there was any surprise left for us. We dumped the gnome-keyring-daemon process in the XFCE Desktop Environment and we could find several occurrences of the user’s password in cleartext. In doing this we encountered some challenges, let’s see how we overcame this in the next section.
Overcoming Challenges
Hunting for password-like strings within a memory dump is a challenging problem because there are really few constraints that might help to identify them.
In particular, the restrictions we might think of are:
- Can only contain printable characters (ASCII
0x20to0x7e) - Minimum length of 6 characters (Unix minimum password length requirement)
Doing a search within a process memory with a regular expression that contemplates the two requirements above yielded hundreds of results. This number of results is too big to handle them efficiently, but there are different approaches that one can take to optimize the search process:
- Only look in Writable memory regions: The password is filled in with data coming from the user, so it can not be a constant. For this reason, it must be stored in memory that has to be writable, such as the stack or the heap.
- Use a “dummy” byte signature: If we assume that the variable containing the password is located within a structure, it could be likely that the bytes surrounding the password are consistent across different executions and, perhaps, across different systems.
Bearing the above in mind, what did we do? We created the “dummy” byte signature by picking a number of bytes before and after the password that would lead to an interesting reduction of potential passwords. Then we tested this against different systems to check whether the password in memory matched the signature or not, and we adjusted the signature accordingly by using less bytes before / after.
With the two optimizations applied to the process, the number of potential passwords found significantly decreased. In the same system where we ran the previous test, it yielded only around 26 results.
We still found a big problem. Reducing that list to just 1 result, the user’s login password. Mimipenguin solves this by obtaining the Shadow hashes from the /etc/shadow file and hashing all the potential passwords until a match is obtained. It is important to highlight that in a situation where the tool is executed within a monitored environment (e.g. Auditd file access monitoring), chances are that the /etc/shadow file will be highly monitored due to its critical file contents. Taking this into account, we decided to use the same method but, instead of reading the /etc/shadow file to obtain the hashes, we found it interesting to use the hashes already obtained from the memory of other processes, such as the child-session process spawned by LightDM that we talked about before.
Problems Encountered
When testing the tool that we developed using the workflow mentioned above, we found that when running it under a fresh install of Fedora (version 31) it was not possible to find the hashes in memory. We realized that this might be caused by SELinux, as it comes installed by default and with the enforce configuration.
To make the tool work in this environment too, we decided to provide an option to use the hashes from the /etc/shadow file.
The Final Tool
After all the challenges and problems were solved, the tool seemed to reliably extract the currently logged in user password relatively quickly.
So what extra value does the tool offer in the end? It extracts the currently logged in user password from any version of Gnome Keyring, allowing to fine-tune the password verification process for those situations where the shadow hash can not be retrieved from memory, and it also offers the option to print the results in JSON to allow better integration with scripts or other tools.
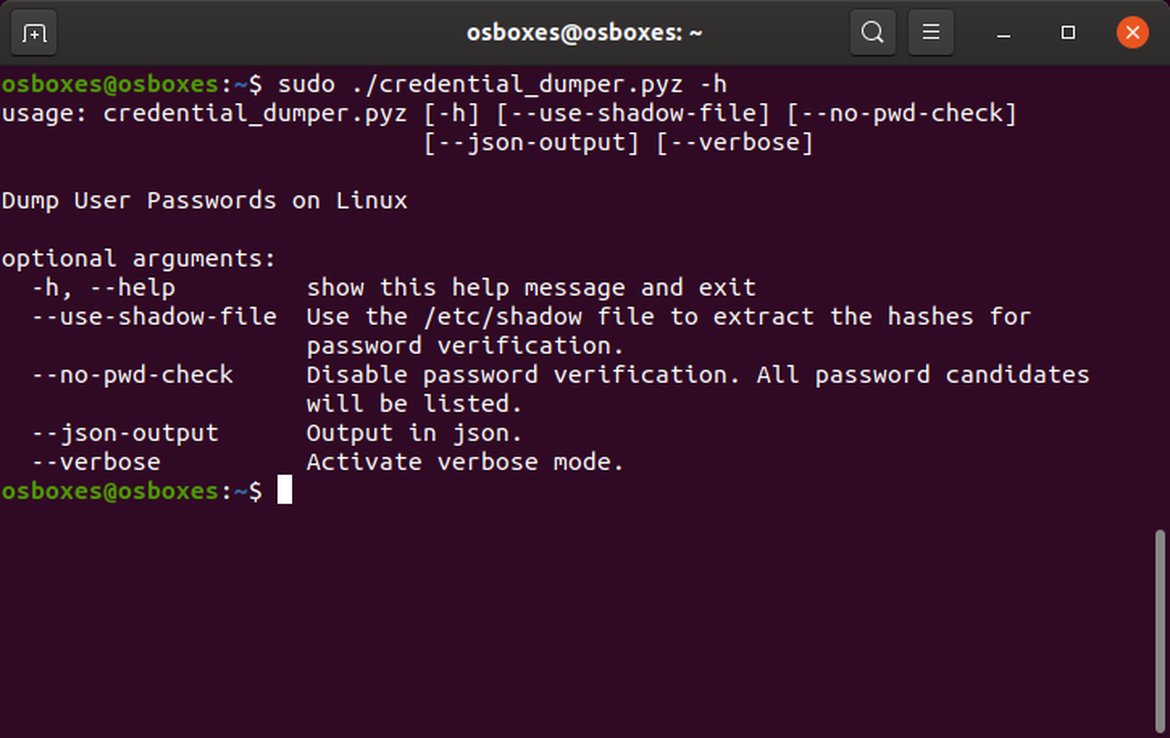
Help option
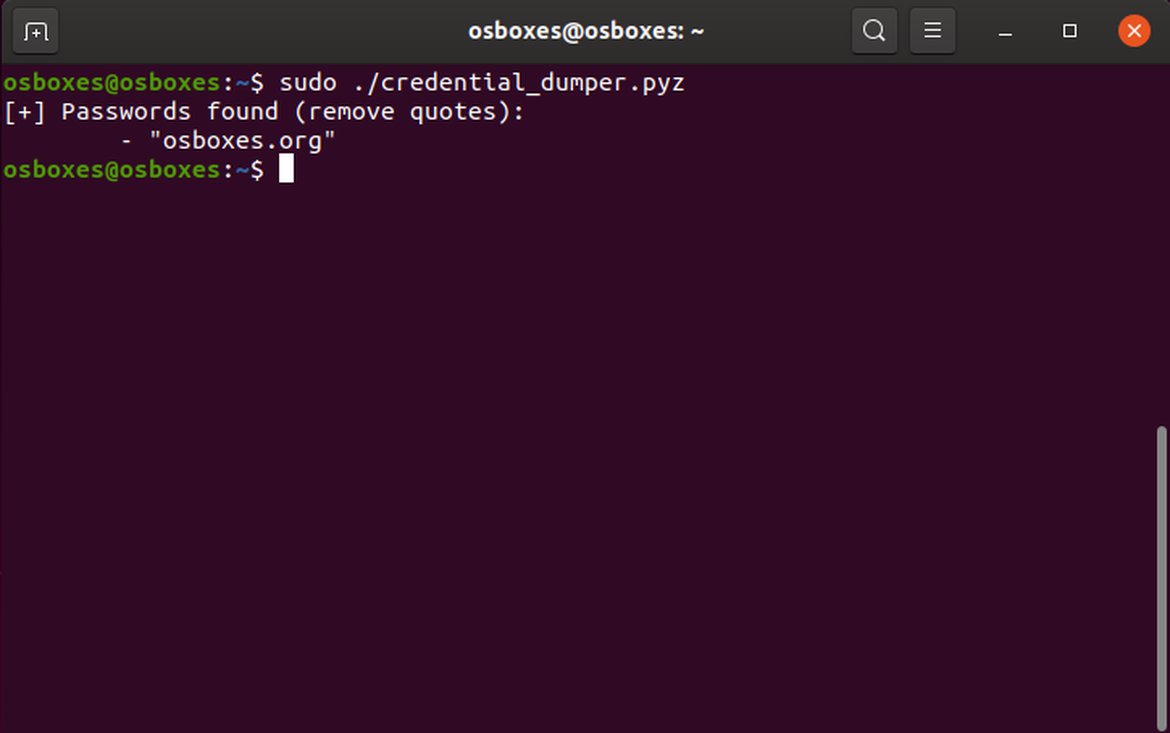
Successful execution
Conclusion
In this post, we have written a small introduction to purple teaming exercises. We explained the stages that such exercises should have, and outlined the content that will be covered in the series.
As part of the Attack stage, we have seen how we could improve existing offensive tooling and created a small tool that increases the efficacy and reliability of Mimipenguin. With this custom tool, the red team would be able to test whether the workstations of the employees of their company are protected against credential dumping attacks for Gnome Keyring or not. This is just one example of how purple teams can respond to a probable attack tactic.
In the next post we will explore how the red team can leverage the AttackIQ platform to execute the developed tool at scale in all the workstations defined in the Scope stage, and make those executions consistent and reproducible.






